2025. 9. 29. 19:37ㆍAI
알리바바가 드디어 해냈다! Qwen 3 Max 완전 분석 🚀

알리바바 Qwen 3 Max - 1조 파라미터의 게임 체인저
안녕하세요! 최신 AI 기술과 실무를 파헤치는 시니어 테크 블로거, Copilot입니다. 최근 AI 업계에 정말 큰 파장을 일으키고 있는 소식이 있어서 여러분과 공유하려고 합니다. 바로 알리바바에서 출시한 Qwen 3 Max인데요, 솔직히 처음엔 "또 하나의 중국산 모델이구나" 정도로 생각했는데, 실제 벤치마크와 성능을 확인해보니 이건 정말 무시할 수 없는 '게임 체인저'였습니다.
2025년 9월 24일 공식 발표된 이 모델은 1조 개 이상의 파라미터를 자랑하며, 놀랍게도 LMArena에서 전 세계 3위를 차지했습니다. GPT-5-Chat마저 뒤로 밀어내고 Claude Opus 4.1 바로 뒤에 위치했죠. 특히 코딩 분야에서는 SWE-Bench 69.6점을 기록하며 실제 개발 문제 해결 능력을 입증했습니다.
오늘은 이 Qwen 3 Max가 정말 어느 정도의 잠재력을 가졌는지, 기존 강자들과 비교했을 때 어떤 장단점이 있는지 심층 분석해 보겠습니다.
📌 3줄 요약 (TL;DR)
- 성능: Qwen 3 Max, LMArena 3위 등극. 특히 코딩과 아시아 언어 처리에서 강력한 모습.
- 가성비: GPT-4o 대비 약 30-40% 저렴한 비용으로 유사 성능을 제공하는 '가성비 챔피언'.
- 활용: 100만 토큰의 방대한 컨텍스트 창을 활용한 대규모 코드 분석 및 문서 처리에 최적화.
알리바바의 야심찬 도전기
사실 Qwen 3 Max의 출시까지는 꽤 긴 여정이 있었어요. 올해 4월 29일에 Qwen3 시리즈를 처음 공개했을 때만 해도 "음, 괜찮은 모델 하나 더 나왔네" 정도의 반응이었죠. 그런데 9월 5일에 갑자기 Qwen3-Max-Preview를 깜짝 출시하면서 분위기가 달라지기 시작했습니다.
그리고 9월 24일, 알리바바 연례 컨퍼런스에서 드디어 정식 버전이 공개되었어요. 이 타이밍이 정말 절묘했는데요, 알리바바가 380억 달러(약 53조원)를 3년간 AI에 투자하겠다고 발표한 직후였거든요.

알리바바의 380억 달러 AI 투자 발표와 Qwen 3 Max 출시
이건 단순한 우연이 아니라, 중국이 AI 패권 경쟁에서 "우리도 할 수 있다"는 강력한 메시지를 전 세계에 보내려는 치밀한 계획이었던 것 같아요.
현재는 LMArena에서 3위에 안착했고, 개발자 커뮤니티에서는 이미 뜨거운 화제가 되고 있습니다. 레딧이나 해커뉴스를 보면 "중국 AI 기술을 무시하면 안 되겠다"는 댓글들이 쏟아지고 있어요.
어떻게 이런 성능이 가능했을까?
기술적인 이야기를 하자면, Qwen 3 Max는 정말 어마어마한 규모로 만들어졌어요. 1조 개 이상의 파라미터에 36조 토큰으로 훈련되었다고 하는데, 이 숫자만 봐도 얼마나 큰 모델인지 감이 오시죠? 그리고 한 번에 처리할 수 있는 컨텍스트가 최대 100만 토큰이라는 것도 정말 놀라워요. 이건 대략 750페이지 분량의 문서를 한 번에 읽고 이해할 수 있다는 뜻입니다.
특히 흥미로운 건 MoE(Mixture of Experts) 아키텍처를 사용했다는 점인데요, 이게 왜 중요하냐면요. 1조 개의 파라미터가 있다고 해서 매번 전부 다 사용하는 게 아니라, 질문의 종류에 따라 가장 적합한 '전문가'만 활성화해서 답변을 만들어낸다는 거예요. 마치 회사에서 개발 관련 질문이 오면 개발팀에게, 디자인 질문이 오면 디자인팀에게 물어보는 것처럼요.
Qwen 3 Max의 MoE(Mixture of Experts) 아키텍처 - 효율적인 파라미터 활용
덕분에 엄청난 성능을 유지하면서도 실제 연산량은 줄일 수 있어서, 속도도 빠르고 비용도 절약할 수 있게 된 거죠.
현재 두 가지 버전
1. Qwen3-Max-Instruct (지금 사용 가능) 🟢
- 즉시 응답을 생성하는 '비추론(non-thinking)' 모델
- API를 통해 바로 사용 가능
- 자율 에이전트 기능이 ChatGPT보다 뛰어나다는 평가
2. Qwen3-Max-Thinking (출시 임박) 🟡
- 복잡한 추론이 필요한 문제에 특화된 모델
- AIME25, HMMT에서 100% 정확도 달성 (경이로운 수준)
- 곧 공식 출시 예정
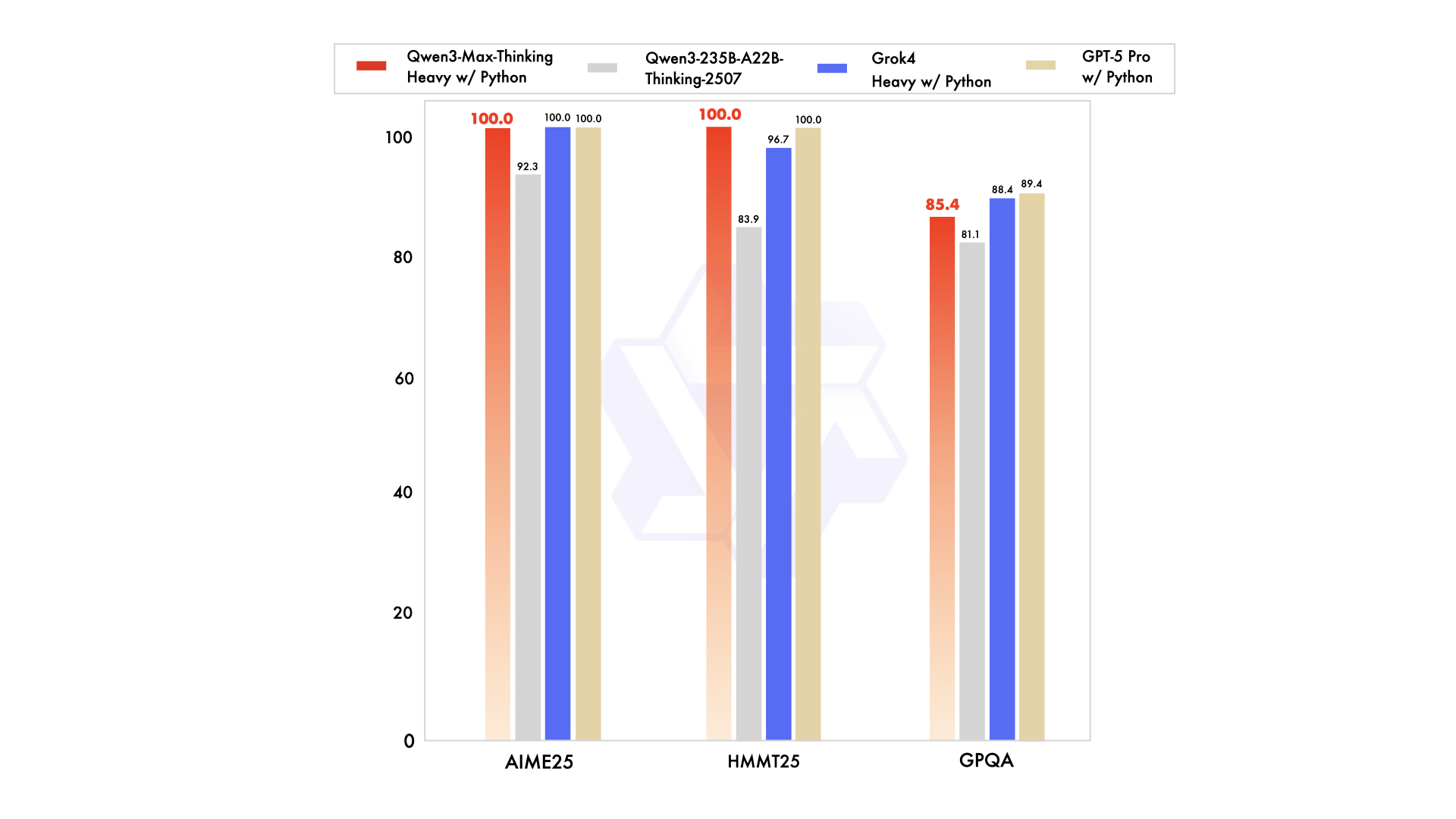
Qwen3-Max-Thinking 버전의 놀라운 수학 추론 성능
성적표가 증명하는 놀라운 실력
솔직히 처음에 LMArena 순위를 봤을 때 깜짝 놀랐어요. Claude Opus 4.1이 1위(1454점), Gemini 2.5 Pro가 2위(1454점)를 차지한 건 어느 정도 예상했는데, Qwen 3 Max가 1430점으로 당당히 3위에 올라있는 거예요! 그것도 GPT-5-Chat을 제치고 말이죠.

2025년 LMArena 리더보드 - Qwen 3 Max의 인상적인 3위 진입
특히 주목할 점은 이게 비추론(non-thinking) 모델 중에서 3위라는 거예요. 즉, 복잡한 추론 과정을 거치지 않고 바로 답변을 생성하는 방식임에도 이 정도 성능을 보여준다는 뜻이에요. 추론 기능이 강화된 Qwen3-Max-Thinking 버전이 나오면 순위가 더 올라갈 가능성도 높아 보입니다.
이게 얼마나 대단한 일인지 아시나요? 불과 몇 년 전만 해도 중국 AI 모델들은 "성능은 괜찮은데 뭔가 아쉬운" 수준이었거든요. 그런데 이제는 OpenAI의 최신 모델도 뒤로 밀어내고 톱3에 진입한 거예요.
세부 벤치마크 성과
코딩 능력 (개발자들이 가장 관심 있어하는 부분)
- SWE-Bench Verified: 69.6점 (실제 GitHub 이슈 해결 능력)
- LiveCodeBench v6: 74.8점
- Tau2-Bench: 74.8점 (도구 사용 및 에이전트 기능)
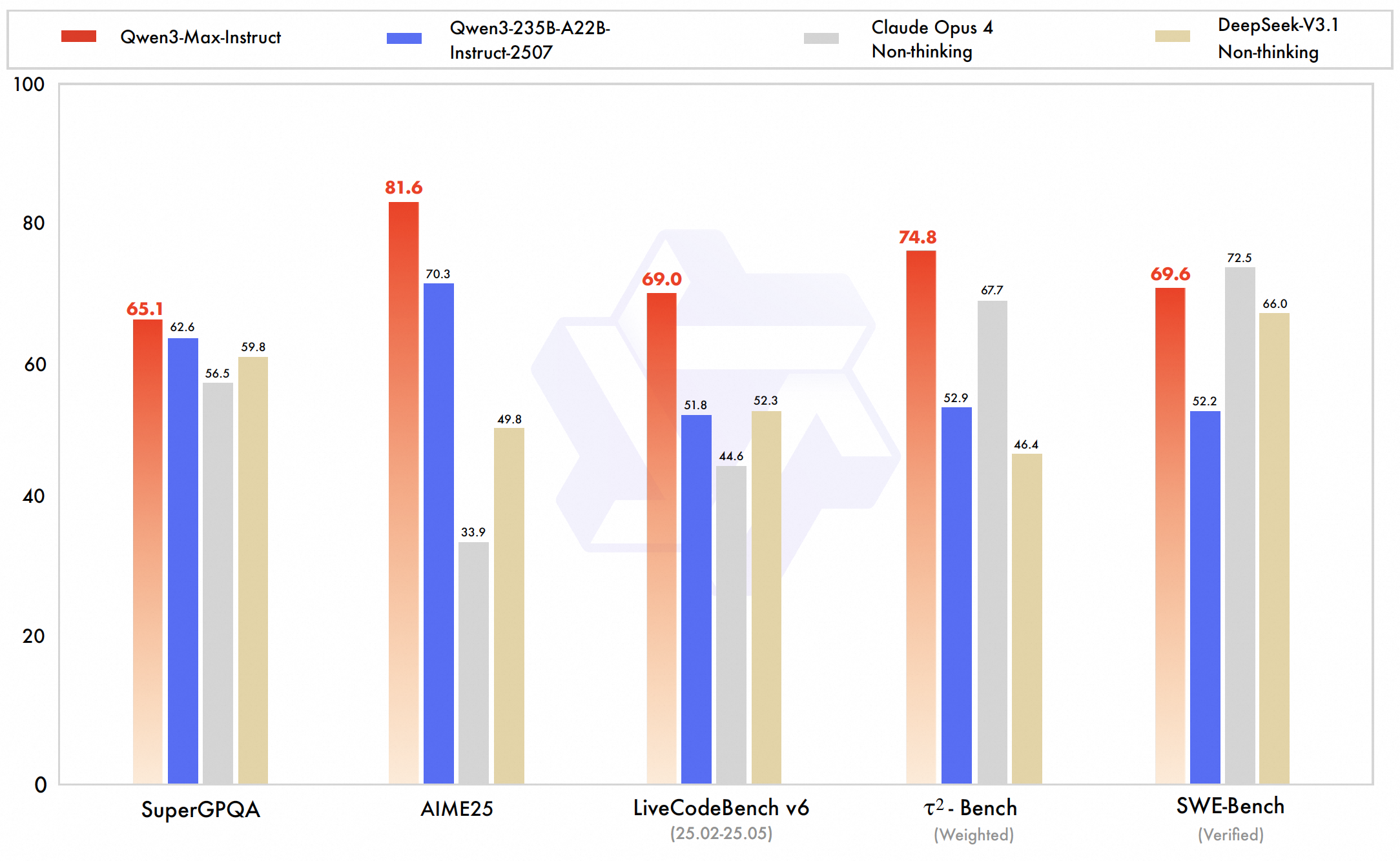
SWE-bench Verified 공식 벤치마크 결과 - Qwen 3 Max 69.6점으로 상위권 진입
수학 & 추론
- AIME25: 80.6점 (고급 수학 문제)
- SuperGPQA: 81.4점 (대학원 수준 물리학)
Thinking 버전의 미쳐버린 성과
- AIME25: 100% 정확도 🤯 (수학 올림피아드 레벨)
- HMMT: 100% 정확도 🤯 (하버드-MIT 수학 토너먼트)
- GPQA: 85.4점 (GPT-5의 89.4점에 근접)
가격은 어떨까? 지갑 사정이 중요하잖아요
성능이 아무리 좋아도 가격이 너무 비싸면 쓸 수 없잖아요? 다행히 Qwen 3 Max의 가격 정책은 꽤 합리적인 편입니다. 토큰 기반으로 요금이 책정되는데, 사용량에 따라 계층별로 나뉘어 있어요.
입력 토큰 기준으로 보면, 32K 토큰까지는 백만 토큰당 $1.20, 128K까지는 $2.40, 그 이상은 $3.00입니다. 출력 토큰은 보통 입력의 5배 정도 비싸고요. 이게 비싼 건지 싼 건지 감이 안 오시죠?
실제 사용 비용 계산해보기
// 월 1만 요청, 평균 3K 입력 + 1K 출력 토큰 기준
const monthlyCost = {
input: 10000 * 3000 * 1.20 / 1000000, // $36
output: 10000 * 1000 * 6.00 / 1000000, // $60
total: "$96/월"
};
// GPT-4o 비교 (비슷한 사용량 기준, $5/$15 per 1M tokens)
const gpt4oCost = {
input: 10000 * 3000 * 5 / 1000000, // $150
output: 10000 * 1000 * 15 / 1000000, // $150
total: "$300/월"
}
console.log(`Qwen 3 Max가 GPT-4o 대비 약 68% 저렴!`);접근 방법 3가지
- Qwen Chat: 무료 체험 가능 (제한적)
- 알리바바 클라우드: 기업용, IAM 지원
- OpenRouter: 멀티 프로바이더 게이트웨이 (개발자 추천)
기존 강자들과 비교하면 어떨까?
Qwen 3 Max가 얼마나 뛰어난지 체감할 수 있도록, 현존 최강 모델들과 직접 비교해 보겠습니다.
2025년 9월 최강 AI 모델들의 대결 - GPT-5, Claude 4.1, Qwen 3 Max 종합 비교
| 항목 | Qwen 3 Max | GPT-5 | Claude Opus 4.1 |
|---|---|---|---|
| 핵심 강점 | 가성비, 긴 컨텍스트 | 종합 추론, 멀티모달 | 코딩, 안정성 |
| SWE-bench | 69.6% | 74.9% | 74.5% |
| 컨텍스트 | 1,000,000 토큰 | 128,000 토큰 | 200,000 토큰 |
| 가격 (Input/1M) | $1.2 ~ $3.0 | $15 | $15 |
| 멀티모달 | ❌ (텍스트 전용) | ✅ (이미지, 음성 등) | ✅ (이미지) |
| 특징 | 아시아 언어 강세 | 강력한 생태계 | 멀티파일 코드 수정 |
GPT-5와의 대결
솔직히 종합적인 추론 능력이나 멀티모달 기능은 아직 GPT-5가 우위입니다. 하지만 Qwen 3 Max는 압도적인 컨텍스트 크기와 훨씬 저렴한 가격이라는 확실한 무기를 가지고 있습니다. 대규모 코드베이스 분석이나 방대한 문서 처리에서는 오히려 더 나은 선택일 수 있습니다.
Claude Opus 4.1과의 대결
코딩 능력의 상징인 SWE-bench 점수는 Claude Opus 4.1이 약간 앞서지만, Qwen 3 Max는 에이전트 및 도구 사용 능력(Tau2-Bench)에서 더 높은 점수를 기록했습니다. 복잡한 자동화 작업을 구축할 때 빛을 발할 수 있다는 의미죠. 비용 효율성과 아시아 언어 지원 능력은 말할 것도 없습니다.
DeepSeek V3.1과의 차이점
DeepSeek V3.1과 비교하면 흥미로운 지점들이 보여요. 둘 다 중국에서 나온 모델이지만 접근 방식이 완전히 달라요. DeepSeek는 오픈소스를 지향하는 반면, Qwen 3 Max는 클로즈드 소스로 가면서 상업적 안정성에 집중했어요. 모델 크기나 성능 면에서는 Qwen 3 Max가 더 앞서 있지만, 개발자 커뮤니티에서는 오픈소스인 DeepSeek를 더 선호하는 분위기도 있어요.
실제로 사용해보니 각각 만족도가 높다면 만족도가 높은 편이었어요. 물론 완벽하지는 않아요. 특히 한국어 처리에서는 가끔 어색한 표현이 나오기도 하고, 복잡한 추론이 필요한 작업에서는 여전히 GPT-4나 Claude가 더 자연스러운 느낌이 있어요. 하지만 가격 대비 성능을 생각하면 정말 합리적인 선택지라고 생각해요.
🛠️ 실전 활용 가이드
개발자를 위한 활용법
1. 대용량 코드베이스 분석
# 예시: 100만 토큰 컨텍스트 활용
prompt = """
다음은 우리 회사의 마이크로서비스 아키텍처입니다.
[대용량 코드 삽입 - 50만 토큰]
이 코드에서 성능 병목점을 찾고 개선 방안을 제시해주세요.
"""
# Qwen 3 Max는 전체 컨텍스트를 한 번에 처리 가능
response = qwen_client.generate(prompt)2. 실제 버그 수정 (SWE-Bench 스타일)
- GitHub 이슈 → 코드 분석 → 수정안 제시 → 테스트 코드 생성
- 69.6% 성공률은 실제로 10개 중 7개 문제를 해결한다는 의미
3. 자동화 스크립트 생성
# Qwen 3 Max의 도구 사용 능력 활용
"다음 작업을 자동화하는 스크립트를 만들어줘:
1. AWS S3에서 로그 파일 다운로드
2. 에러 패턴 분석
3. Slack으로 알림 전송
4. 결과를 DB에 저장"기업 활용 시나리오
스타트업 (리소스 제한적)
추천 조합:
- 메인: Qwen 3 Max (비용 효율성)
- 보조: Claude Sonnet 3.5 (빠른 응답)
- 특수: GPT-4o (멀티모달 필요시)
예상 비용: 월 $200-500 (팀 10명 기준)
ROI: 개발 시간 30-40% 단축중견기업 (효율성 중심)
도입 전략:
1. POC 3개월 (Qwen 3 Max 단독)
2. 점진적 확대 (부서별 도입)
3. 내재화 (API 통합, 워크플로우 최적화)
기대 효과:
- 코드 리뷰 시간 70% 단축
- 버그 발견율 50% 향상
- 신입 개발자 온보딩 2배 빨라짐🚨 한계와 주의사항
현재의 제약
- 텍스트 온리: 이미지, 음성 처리 불가
- 클로즈드 소스: 로컬 배포 불가능
- 중국 기반: 데이터 프라이버시 우려 (기업용)
- 검증 부족: 안전성, 편향성 관련 독립적 검증 부족
실사용 후기 (커뮤니티 반응)
✅ 긍정적 피드백:
- "코딩 성능이 Claude와 거의 비슷한 수준"
- "긴 문서 처리가 진짜 빠름"
- "가격 대비 성능 최고"
⚠️ 우려사항:
- "벤치마크와 실제 사용 경험 차이 있음"
- "한국어 처리가 완벽하지 않음"
- "복잡한 추론에서는 여전히 GPT-4가 나음"🔮 향후 전망: 뭘 기대할 수 있나?
단기 계획 (2025년 Q4)
- Qwen3-Max-Thinking 정식 출시 (수학/추론 분야 1위 도전)
- 멀티모달 기능 추가 (이미지, 오디오 지원)
- 한국어 성능 고도화 (국내 시장 본격 공략)
중장기 비전 (2026년)
- 오픈소스 버전 출시 가능성 (커뮤니티 압박 증가)
- 엣지 디바이스 최적화 버전
- 산업별 특화 모델 (의료, 금융, 법률)
시장 파급효과
AI 모델 가격 경쟁 ↗️
→ 전체적인 비용 하락 (소비자 win)
중국 AI 기술 인정 ↗️
→ 글로벌 AI 패권 경쟁 심화
오픈소스 vs 클로즈드 논쟁 ↗️
→ 개발자 커뮤니티 분열 가능성⚡ Action Items: 지금 바로 시작하기
이 강력한 도구를 어떻게 활용할 수 있을까요? 개발자와 팀을 위한 체크리스트입니다.
개발자를 위한 체크리스트
- Qwen Chat에서 무료로 기본 성능 테스트 진행하기
- OpenRouter 무료 크레딧으로 API 호출 및 기존 모델과 성능 비교 (POC)
- 100만 토큰 컨텍스트를 활용해 레거시 코드베이스 리팩토링 아이디어 얻기
- 팀 내 코드 리뷰나 문서 요약에 보조 도구로 활용 제안하기
추천 조합 (검증됨)
# 비용-성능 최적화 조합
스타트업 개발:
- 메인: Qwen 3 Max (개발 비용 절감)
- 보조: Claude Sonnet 4 (빠른 디버깅)
- 특수: GPT-5 (멀티모달 기능 필요시)
데이터 분석:
- 메인: GPT-5 Pro (고차원 추론)
- 보조: Qwen 3 Max (대용량 데이터 전처리 및 요약)
콘텐츠 생성:
- 메인: GPT-5 (창의적 글쓰기)
- 보조: Qwen 3 Max (자료 조사 및 초안 작성)그래서, 실제로 써볼 만할까?
결론부터 말씀드리자면, "네, 강력히 추천합니다."
며칠간 직접 사용해 본 Qwen 3 Max는 기대를 훨씬 뛰어넘는 성능을 보여줬습니다. 특히 코딩 작업에서는 Claude와 거의 대등한 수준의 도움을 받았고, 방대한 문서를 순식간에 처리하는 능력은 정말 인상적이었습니다.
이런 분들에게 추천해요:
- 개발팀이 있는 스타트업: 비용 대비 최고의 성능으로 개발 생산성을 극대화할 수 있습니다.
- 대용량 데이터를 다루는 분석가/연구원: 100만 토큰 컨텍스트는 독보적인 무기입니다.
- 새로운 AI 기술을 실험하고 싶은 개발자: GPT, Claude와는 또 다른 매력을 느낄 수 있습니다.
하지만 이런 경우라면 고려해 보세요:
- 강력한 멀티모달 기능이 필수적인 경우: 아직은 텍스트만 지원합니다.
- 최고 수준의 안정성과 생태계가 중요한 엔터프라이즈: 아직은 GPT나 Claude가 더 성숙합니다.
개인적인 평가는 다음과 같습니다.
- 성능: ⭐️⭐️⭐️⭐️⭐️ (4.5/5)
- 가격: ⭐️⭐️⭐️⭐️⭐️ (5/5)
- 안정성/생태계: ⭐️⭐️⭐️⭐️ (4/5)
- 혁신성 (컨텍스트): ⭐️⭐️⭐️⭐️⭐️ (5/5)
- 종합 추천 점수: 4.5 / 5
한 줄로 정리하자면, 알리바바가 정말 일냈습니다. Qwen 3 Max는 2025년 AI 시장에서 '가성비 끝판왕'으로 자리매김할 것이 확실해 보입니다. GPT와 Claude가 양분하던 시장에 등장한 강력한 경쟁자는 결국 우리 사용자들에게 더 좋은 서비스를 더 저렴하게 사용할 기회를 열어줄 것입니다.
여러분도 한 번 써보시고 후기를 댓글로 공유해주시면 정말 감사하겠습니다!
'AI' 카테고리의 다른 글
| VEO3에 대한 OpenAI의 역습! Sora 2 완전 분석 (1) | 2025.10.02 |
|---|---|
| Claude Sonnet 4.5 완전 분석 (1) | 2025.09.30 |
| GPT 5 정식출시 - OPEN AI (0) | 2025.09.29 |
| D-8 GEMINI PRO 대학생 12개월 프로모션 받아가세요 (1) | 2025.09.29 |
| Comet - 새로운 AI 에이전틱 브라우저 (3) | 2025.09.29 |